Given
a mass of numbers, how do you make sense of them? The quantities of macroeconomic
data that are available are far beyond the ability of any person to understand
without condensing and summarizing them in some way. The numbers in the accompanying
data set represents only a tiny fraction of the available macroeconomic data,
but even so, they are far too many for us to see patterns without condensing
them into just a few well chosen summary measures. There are several standard
measures that we can use. Statisticians call these measures descriptive statistics.
In this chapter we examine several of the more common ways to describe datasets,
including graphical methods.Before we begin,
it is helpful to tell the SPSS program that our data is annual data from 1929
to 1996. This will make it easier when we want to select a subset of years and
look at them alone, or perhaps compare them to a different time period. The
method for specifying that the data are annual time series is straightforward.
- After you
have started the program and loaded the dataset, click on Data in the
menu bar.- Click on
Define Dates;- In the
Cases Are box, select Years;- In the
First Case Is box type 1929;- Then, click
OK.SPSS will define
two new variables, Year_ and Date_, which are added to the data set.As a first step
in analyzing data, it is useful to look at a visual presentation of the numbers.
SPSS allows its users to easily create graphs, so let's begin by plotting GDP
over the entire period, 1929-1996. The following steps will accomplish this.
- Choose
Graphs from the menu bar;- Click Line;
- In the
Line Chart Box that appears, select the button for Values of individual
cases;- Click Define;
- Highlight
GDP in the alphabetical list of variables and click the arrow to put it
into the Line Represents box;- In the
Category Labels box, select the button for Variable;- Highlight
year (not year_) in the variable list on the left, and click the arrow
to put it into the Variable box;- Click OK.
At this point, SPSS
will create a chart. If you want to edit the chart (for example, change the
labels of the axes), click on Edit. SPSS puts the chart into edit mode where
you can double click on anything you want to change. After editing, your chart
should look like Chart 1.
In Chart 1, GDP
ranges from a little more than 50 billion to nearly 8,000 billion. The scale
covers such a wide range of values that GDP in the early years looks as if
it is close to zero, and the Great Depression of the 1930s doesn't appear
on the graph in any meaningful way. When graphs cover such a wide range of
values, they hide a lot of detail and may be very misleading.As an illustration
of this point, let's re-create the GDP graph for a subset of the years in
the data set. We will follow the same steps as above, but this time before
we create the graph, we will tell SPSS to use only the years between 1929
and 1940. This will give a close-up picture of the Great Depression. In order
to select 1929-1940, do the following:
- Click on
Data in the menu bar;- Choose
Select Cases;- Click the
button "Based on time or case range . . ." and click Range;- In the
First Case box, type 1929 and type 1940 in the Last Case box;- Click Continue,
and then OK. (Make sure the Unselected Cases Are "Filtered" is Selected;
this is the default and otherwise, all other years will be deleted!)Once you have selected
the subset of years, 1929-1940, you can repeat the steps in creating the graph.
As long as you do this right after the previous graph, everything will be set
up to produce the same kind of graph and you will not have to repeat all the
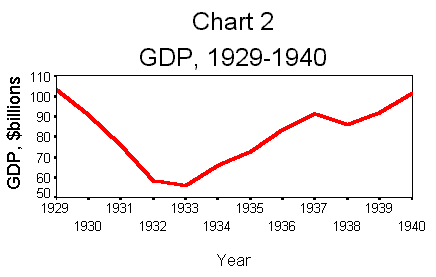
steps. With some editing of axes labels, your graph should look like Chart
2.
Note the difference
in the impressions created by Charts 1 and 2. Both are graphs of GDP for the
same country over a similar set of years. However, since Chart 1 has a much
larger scale (56 to 7,576) than Chart 2 (56 to 103), the tragedy and devastation
of the Great Depression is lost in the graph of the longer period.GDP is a variable
that continually grows over time. As a consequence, earlier values get swallowed
by the huge increases that take place over a long time period, and dramatic
changes in the early periods do not even show up. This is not true for every
variable, however. Unemployment rates, for example, may experience a trend
over a decade or more, but in general they tend to fluctuate within a relatively
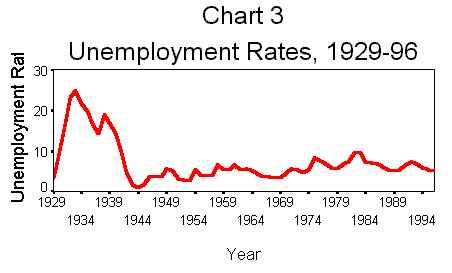
narrow range. In Chart 3, unemployment rates are graphed for the entire
time period, 1929-1996. Note how the Great Depression stands out.How big is GDP?
We know that production is composed of consumption goods, investment goods,
government purchases of final goods and services, and net exports, but which
of these are the largest? The smallest? Has consumption or investment become
a larger or smaller share of GDP over time? Do their shares vary? Similar questions
can be posed on the income side of GDP measures. For example, are wages and
salaries (labor income), or profits, a larger share of total income? Have their
shares changed? Do they vary much? These are some of the questions that can
be answered with descriptive statistics.Let's compare
the relative size of the shares of GDP that are made up by consumption, investment,
government, exports, and imports. In order to do this, we first must compute
each components share of GDP. The following steps accomplish this.
- Select
Transform from the menu bar;- Choose
Compute . . .;- In the
Target Variable box, type the name of the variable that will be consumption's
share of GDP; it is always a good idea to give new variables names that
will remind you what they are, so call it cs;- In the
Numeric Expression box type the formula: (c/gdp)*100;- Click OK;
- Repeat
the steps for investment share: is = (i/gdp)*100;- Repeat
for government share: gs = (g/gdp)*100;- Repeat
for export share: exs = (ex/gdp)*100;- Repeat
for import share: ims = (im/gdp)*100.Now, we are ready
to summarize this data. This is the easy part.
- Select
Statistics from the menu bar;- Choose
Summarize, and then Descriptives . . .;- Highlight
cs and click it into the box labeled Variables;- Do the
same for is, gs, exs, and ims;- Click OK.
SPSS brings to the
front the output window whenever you run a routine that generates output. The
output window presents the data summary in a table with seven columns, and rows
for each variable. The columns list the variable names, the mean
of each variable, the standard
deviation (Std Dev), the minimum value, the maximum value, the number
of observations, and the variable labels, if any. The SPSS output is in Table
4. Most of these summary measures are either self explanatory, or you probably
know them from other sources.
Table
4
Shares of GDP
Variable Mean Std
DevMinimum Maximum Valid
NEXS
6.08
2.38
1.97
11.29
68IMS
6.20
3.05
2.85
12.59
68IS
13.844.04
1.8818.8
68GS
20.99
6.71
8.96
48.07
68CS
65.31
6.33
49.39
83.11
68
The mean is one
type of measure of central tendency. It is also an average, although
it is not the average. In fact, there several measures called "average,"
each one of which is a measures of the "center" of the data, or central tendency.
The mean of a variable X is usually symbolized with the Greek letter m (mu)
for an entire population or, for a sample which is a subset of the population,
the letter x with a bar over it. (I cannot reproduce this, so I call it x-bar.)
Algebraically, it is defined asx-bar = (x1
+ x2 + . . . + xn)/n = (åi xi)/n.Other commonly
used averages are the median
and the mode. The median puts
½ of all observations below it and the other half above when they are
arrayed from lowest to highest. For example, since there are 68 observations,
the median of cs is the midpoint between the 34th and 35th values, when cs
is arrayed in order from smallest to largest (and not by date or year).
The mode is the most common observation. For data such as this, it is not
a relevant or commonly used measure because no value is repeated.The standard
deviation is a measure of dispersion,
or variation, of a variable around its mean. The larger the standard deviation,
the greater the amount of variation in the variable being measured. For example
the standard deviation of the export share is 2.38, while for the import share
it is 3.05. We can say from this that exports vary less than imports as a
share of GDP. The standard deviation is usually symbolized with the roman
letter s for a sample, and the Greek letter s (sigma) for a population. Algebraically,
it is defined as the square root of the variance, where the variance equalss2
= [åi (xi - x-bar)2]/(n-1).By definition
s = Ö s2.The next two
values, the minimum and maximum, are used to find the range
of a variable. The range is another measure of variation, or dispersion. It
is defined in two ways:range = (minimum
value, maximum value),or alternatively,
range = (maximum
value - minimum value).For example,
for the share of consumption in GDP, the range is (49.39, 83.11), or 33.72
(calculated as 83.11-49.39)Note that in
Table 4, the components of GDP that
have the largest range (and standard deviations) are government and consumption.
(Government's variation is centered around a much smaller mean, however.)
This may be somewhat surprising, since we do not ordinarily think of our consumption
as varying a lot. In order to follow up on this, it is useful to graph the
variables cs, gs, and is, to see how they moved over time.
- Choose
Graphs from the menu bar;- Click Area;
- In the
Area Chart Box that appears, select Stacked, then select the button for
Values of individual cases, then click Define;- Highlight
cs in the alphabetical list of variables and click the arrow to put it
into the Area Represents box; do the same for gs and is;- In the
Category Labels box, select the button for Variable;- Highlight
year in the variable list on the left, and click the arrow to put it into
the Variable box;- Click OK.
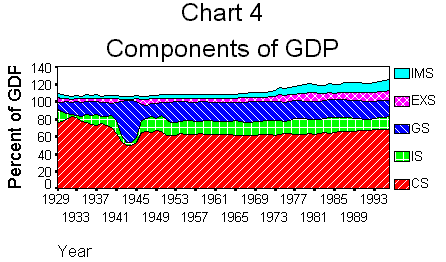
A lot of the variation
in gs and cs occurs during World War II (see Chart 4).
This is not surprising
if you think about it. On the one hand, consumption was held down artificially
through rationing, and through a lack of production of consumer goods. On
the other hand, government spending on final goods and services skyrocketed
due to the purchase of tanks, airplanes, ships, rifles, uniforms, and the
services of millions of soldiers.If we re-calculate
the descriptive statistics using data from 1950-1996, a different picture
emerges. The standard deviations of both the consumption share of GDP and
the government share are less than other variables. Any guess which have the
largest standard deviation?Before moving
on, you may find it of interest to perform similar types of analyses on the
income side of GDP. Remember from Chapter 2 and Table 3
that national income is divided into the five main components: wages and salaries,
proprietor's income, rental income, corporate profits, and interest income.
Divide each of these by national income (ni in the data set), and proceed
along the same lines as above.Chart 3 plotted
the unemployment rate for the entire labor force from 1929 to 1996. The outstanding
feature of that graph was the extraordinarily high rates that occurred during
the 1930s, reaching nearly 25 percent in 1933. Other recessionary periods (for
example, 1974-75 or 1981-82) show higher than usual unemployment rates, but
they are small hills in comparison to the Mt. Everest of the 1930s.The fact that
unemployment increases during a recession is one commonly studied pattern.
Since the 1960s and the Civil Rights movement, economists have also been more
aware of the patterns of employment and unemployment by race, ethnicity, and
gender. Official government statistics of unemployment began to identify the
race and ethnicity of non-whites and Hispanics in the early 1970s. Statistics
for whites began in the 1950s, along with separate measures for (white) males
and females.Because unemployment
measures vary over the course of the business cycle, as well as by age, by
race, and by gender, it is important that comparisons of descriptive statistics
are based on the same set of years. For example, suppose we want to compare
unemployment rates for blacks and whites. We could compare black and white
men, women, or teens. In either of these comparisons, the limiting series
is the one for blacks since it begins in 1972. We will compare all three cases
(men, women, and teens), along with the measure of unemployment for the whole
labor force.
- Choose
Data from the menu bar;- Choose
Select Cases, and set the cases to 1972 to 1996;- Click okay.
- Select
Statistics from the menu bar;- Choose
Summarize, and then Descriptives . . .;- Highlight
bm20u and click it into the box labeled Variables;- Do the
same for bw20u, btu, wm20u, ww20u, wtu, and ur;- Click OK.
Note that there
is a hierarchy of unemployment rates which essentially contains four categories.
From lowest to highest, they are white adults, black adults, white teens and
black teens. White adults have rates below the economy-wide average (ur) while
black adults are far above it. White teens somewhat above black adults and black
teens are in an entirely different universe of unemployment rates.Why do teens
have higher unemployment than adults? One reason is because teens change jobs
more often than adults. They may be searching for that first really good job
and are also less likely to be tied down with family responsibilities. But
why are black teen rates so much higher than the rate for white teens? And
why are white rates so much lower than black rates? I leave it to the reader
to supply their own conjectures. It is clear, however, that proving something
beyond the shadow of a doubt will require additional data beyond that contained
in this dataset.One change in
our economy is the increase in women's labor force participation rates. Recall
that the labor force is made up of the subset of non-institutionalized adults
(16+ in age) that are either working or looking for work. (The institutionalized
population is composed of people in jail, the military, and mental institutions.)
Increasing women's labor force participation is a phenomena that goes back
to the 19th century. The changes we see today are reflective of the fact that
women have always worked, albeit not for pay, nor in a formal market economy.
As more and more production that used to occur inside households is moved
out to the market economy, more women work in the market economy. You can
view this change by doing the following:
- Choose
Data from the menu bar;- Choose
Select Cases . . ., then select All Cases, and click OK.- Choose
Graphs from the menu bar;- Click Line;
- In the
Line Chart Box that appears, select Multiple; then select the button for
Values of individual cases; then click Define;- Highlight
wm20 (labor force participation rate of white males, 20 and older) in
the alphabetical list of variables and click the arrow to put it into
the Line Represents box; do the same ww20;- In the
Category Labels box, select the button for Variable;- Highlight
year in the variable list on the left, and click the arrow to put it into
the Variable box;- Click OK.
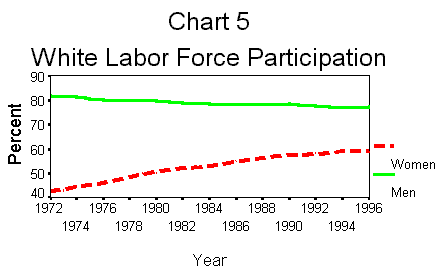
The series are white
men's labor force participation (wm20) and white women's labor force participation
(ww20). The results, after some editing, should look like Chart 5.Note the upward
trend in women's rates. Surprisingly, perhaps, is the slight downward trend
in men's rates. This may be evidence of the truth contained in the joke: "Beware
a man who supports women's rights; he's usually just about ready to quit his
job."Chart 5 was created
using data for whites because that is the longest series in the dataset with
gender specific labor force participation rates. It naturally leads to the
question: Are participation rates for black men and women changing in a similar
way?Recall from Chapter
1 and your macro textbook that inflation is the percentage change in a price
index. In most cases, we use the CPI to measure inflation because price changes
for consumer goods directly affects us while price changes in producer goods
or GDP only have an indirect affect. Since producer price inflation may be passed
on through an increase in consumer prices, it seems reasonable to expect that
the two indexes would move together. Let's check, and while we are at it, we
might as well see if the GDP deflator also tracks along with the other two.First we need
to calculate the percentage change in the CPI, PPI, and GDP deflator. Before
you do this, however, make certain that the Select Cases is set to All Cases.
SPSS will do the Compute routine we specify on all cases regardless of the
setting of the Select Cases, but we will want to graph all the available data.
The formula for calculating the rate of inflation is
[(CPIt
- CPIt-1)/CPIt-1] * 100,which is the
simple percentage change formula:
[(new value
-old value)/old value] * 100.In SPSS, the
way to specify the previous value of a variable is with the Lag operator.
We will do this as follows:
- Choose
Transform from the menu bar;- Select
Compute . . .;- In the
Target Variable box type pcpi;- In the
Numeric Expression box, type ((cpi - lag(cpi))/lag(cpi))*100;- Click OK.
Note that the expression
for the calculation of the inflation rate uses lag(cpi) as the previous value
of the cpi; in the definition of the formula, it is equivalent to CPIt-1.After you have
calculated the rate of inflation for the CPI, do the same for the PPI and
the GDP deflator (gdpef). Call these new variables the pppi and the pgdp.
As a first check, lets calculate the descriptive statistics for all three.
You should get means and standard deviations that are PGDP(3.30, 4.01), PPPI(3.40,
3.93) and PCPI(3.45, 4.34). Note the similarity in their means and variation.
Now let's graph them, following the steps for a multiple series line chart.The results are
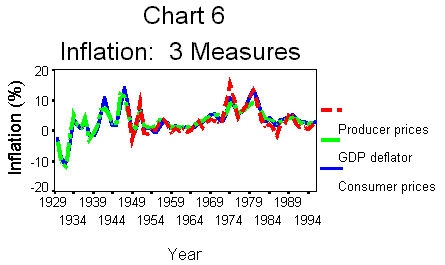
displayed in Chart 6.Several important
patterns are displayed in Chart 6. First, note how prices fell during the
1930s. Falling prices are called negative inflation or, more correctly, deflation.
Second, there were two major periods of high inflation. This was during
and after World War II, and again in the 1970s. Can you explain why?One of the primary
reasons for calculating inflation is to enable us to adjust GDP and other
monetary variables for changes in prices. Looking back at Chart 1 for example,
we see an ever rising GDP. Yet much of the increase over time is a result
of higher prices for our output. In other words, not all the increase in GDP
that shows up in Chart 1 actually represents more goods and services. Some
of it is just higher prices for the same goods and services. If we want to
understand how our economy has grown, we really need to look at variables
after the effects of inflation are taken out. This distinction, between variables
which are not corrected for inflation and those that are, is the difference
between nominal and real variables. Real GDP, for example, is
the value of GDP after all the effects of higher prices have been removed.Real variables
are nominal variables that have been adjusted so that they are valued at constant
prices. This sounds a lot harder to do than it actually is, given that we
have price indexes that allow us to easily do the necessary adjustment. Using
GDP for our example, we can define real GDP as: Real GDP = (Nominal GDP/GDP
deflator) * 100.In SPSS this
is easily done:
- Choose
Transform from the menu bar;- Select
Compute . . .;- In the
Target Variable box type rgdp;- In the
Numeric Expression box, type (gdp/gdpdef)*100- Click OK.
This gives a new
series, called rgdp, which is real GDP. Since the GDP deflator has 1992 as its
base year, real GDP is the value of GDP, 1929-1996, when all goods are measured
in 1992 prices. Economists sometimes speak of real GDP as constant price GDP,
or constant dollar GDP; the reason for this terminology should be obvious. We
can compare real GDP to the unadjusted, or nominal GDP, but the results would
not tell us much. Of greater interest is a comparison of the growth rates of
GDP in real and nominal terms. In order to do this, we must first calculate
the growth rates, and then perform the descriptive statistics routine.
- Choose
Transform from the menu bar;- Select
Compute . . .;- In the
Target Variable box type rgdpg;- In the
Numeric Expression box, type ((rgdp-lag(rgdp))/lag(rgdp))*100;- Click OK.
Do the same for
the nominal value of GDP (gdp in the dataset). Note that the formula is, once
again, the percentage change formula.After calculating
the growth rates, we are ready to run the Descriptives routine:
- Select
Statistics from the menu bar;- Choose
Summarize, and then Descriptives . . .;- Highlight
rgdpg and click it into the box labeled Variables;- Do the
same for gdpg;- Click OK.
The results will
be displayed in the output window which comes to the top after the calculations
are performed. The means and standard deviations should be RGDPG(3.43, 5.53)
and GDPG(6.91, 7.72). In other words, from 1929 to 1996, the average rate of
growth of real GDP was 3.43 percent and the average for nominal GDP was 6.91
percent. The difference is approximately equal to the rate of inflation as measured
by the GDP deflator.The quantity of
money in circulation varies over time and is proportional to GDP. It is not
a constant proportion of GDP, however, because banks and other lending institutions
(for example, credit unions) create our money supply and, when times are good,
they tend to create more of it. A complete description of the mechanism through
which banks create money is beyond the scope of this workbook, but the basics
are fairly easy to explain. When I deposit my paycheck in the bank, I behave
as if it is still my money, and indeed, it is. Because we operate under a fractional
reserve banking system, banks do not keep every penny of every deposit on hand.
They lend out their deposits, which is how they make profits. After all, they
have to operate my checking account and pay me 2.0% interest on the money in
my savings account.From the standpoint
of the bank, they are obligated to pay me my money whenever I ask for it,
or to honor any checks I write on my account, and transfer the money to another
bank where my check is deposited. When they loan out my deposit, they create
new money. This follows because there is another person, the borrower, who
is walking around spending the loan they just received. They may use it to
buy a new car, or a refrigerator, or whatever; the point is that both myself
(the depositor) and the other person (the borrower) have money--and it is
the same dollars.Obviously, if
every depositor showed up at the same time and requested their money, the
bank would not be able to pay up. This happened in the 1930s when rumors of
insolvent banks spread through a town, everyone rushed down to the bank to
get their money out before it went broke, and the ensuing withdrawals caused
the bank to collapse long before every depositor was paid off. Waves of bank
failures were one of the main causes of the spread and intensification of
the Great Depression.In response,
the federal government created the Federal Deposit Insurance Corporation (FDIC).
The FDIC requires banks to pay into an insurance pool an amount that varies
with the size of the bank's deposits. Since we know our money is insured,
we tend not to worry about it, even if our own bank fails. As a result, runs
on banks are nonexistent. (This system creates its own hazards due to the
lack of incentives for depositors to be vigilant in watching their banks;
this is almost certainly a lesser problem than bank runs.)So, to summarize
the story so far, banks create money and the quantity of money varies with
GDP. We can be more explicit. The relationship between the money supply and
GDP is summarized in the equation of exchange:MV = PY,
where M is the
money supply (usually M1 or M2), V is velocity (we will return to this in
a moment), P is the price level, and Y is real GDP. Given the definitions
of P and Y, it follows that PY is nominal GDP. Velocity is defined as the
rate at which money turns over. That is, it tells us the average number of
times each dollar bill gets spent in the creation of nominal GDP. For example,
if PY is 500, and M is 100, then V would be 5, implying that on average each
dollar bill is spent five times on elements of GDP.If velocity were
constant, and if we had good control over how much money banks created, then
we could predict fairly closely what nominal GDP would be. Economists that
belong to the school known as monetarism use this relationship fairly
successfully to predict GDP. (That is, they fail about as badly as everyone
else that predicts GDP, but no worse.)Initially, when
monetarism presented itself as an alternative to Keynesianism in the 1950s
and 1960s, monetarists held that velocity was relatively stable, or at least
predictable. Lets examine that claim. We can calculate velocity by dividing
nominal GDP by the money supply. Depending on whether we use M1 or M2 as our
definition, we will get a different set of values for velocity; that is not
a problem as long as we are consistent in the definition of money. Lets compare
M1 and M2 velocity.
- Choose
Transform from the menu bar;- Select
Compute . . .;- In the
Target Variable box type vm1;- In the
Numeric Expression box, type gdp/m1.- Click OK.
- Repeat
the procedure for the M2 definition, and call it vm2.- Choose
Statistics from the menu bar;- Choose
Summarize, and then Descriptives . . .;- Highlight
vm1 and vm2 and click them it into the box labeled Variables;- Click OK.
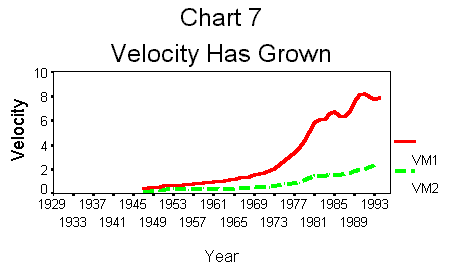
Note that the velocity
of M1 is quite a bit higher than M2. Algebraically, this follows from the fact
that M2 includes M1 and therefore it must be at least as big. A graph of vm1
and vm2 shows that they have grown significantly over time (Chart 7).When velocity
grows, it implies that households and businesses are conserving on their holding
of money so each dollar turns over more often.People are more
likely to conserve on their money holdings when the opportunity cost of holding
money rises, or when it becomes easier to get along with less due to institutional
changes such as credit and debit cards, money market accounts, and so forth.
Given the scope of these changes, as well as the high interest rates of the
1970s which made it expensive to hold money (opportunity cost of money is
foregone interest), velocity has been on an upward trend. As a result, the
calculated descriptive statistics are meaningless. This follows from the fact
that the variable is constantly growing. The mean of velocity, 1947-1994,
is equivalent to calculating your average height between the ages of 2 and
15. We can do it, but it is not clear what it tells us. The graph (Chart 7)
is far more insightful.The point was
made above that it costs money to hold money. That is, money is a store of
value--wealth--that could potentially be held in many different forms, many
of which pay interest. When someone chooses to hold money instead of an interest
paying asset, they forgo the interest payment they could earn in return for
having the convenience of holding money. Money is the most easily spent form
of wealth, or in economic jargon, the most liquid. Bonds and other interest
paying assets cannot be spent directly but must be exchanged for money first.In addition to
serving as the cost of holding money, interest rates are also important because
the are the price at which firms can borrow money from financial institutions,
or lend out money if they are a financial institution. Lenders and borrowers
recognize, however, that since the value of money changes over time, the dollars
that are paid back are never worth the same as the dollars that were borrowed.
For example, suppose the inflation rate is 10% and you borrow $1,000 for one
year. When you pay back the principal, it purchasing power will have shrunk
by 10% and only be worth $900 in terms of the dollars originally borrowed.
If the interest rate was 10%, then it just offset the loss of purchasing power
of the dollars paid back, and the real cost of the loan in terms of goods
is 0%. This follows from the fact that 10% more dollars ($1,100) buys exactly
the same quantity of goods and services after one year that $1,000 bought
at the start of the year.To be specific,
we can say that the real
rate of interest is equal to the interest rate minus the rate of inflation.
We call the interest rate charged by a lender the nominal
rate of interest in order to indicate that it is not inflation adjusted,
and to distinguish it from the real rate. The algebraic representation of
this relationship isr = i - p ,
where p is the
symbol used to signify inflation.Note that firms
must guess r since when they borrow they cannot be certain what p will be
over the life of the loan. All they know for certain is the nominal rate,
i, and their expectation of inflation. Since firms base their investment decisions
on the real rate, economists pay a lot of attention to it. It is generally
assumed that, all else equal, a higher real rate leads to less investment,
and a lower real rate leads to more. Furthermore, lenders as well as borrowers
try to anticipate inflation and adjust the nominal rate in order to earn a
desired real rate. This raises the question whether real rates of interest
change over time or not. If nominal rates and inflation move together, then
real rates would be more or less constant. We can check this with our data
set.First, lets graph
nominal rates and inflation, using the percentage change in the CPI as our
measure of inflation. For nominal interest rates, we can use the prime
rate, which is the interest rate that banks charge their most favored
corporate customers. The procedure for graphing these variables is the same
with earlier graphs of multiple series. You may want to restrict the data
using the Select Cases . . . since the prime rate is only available from 1945
to 1996. Once you obtain your graph, it should look like Chart 8.We see that when
inflation spiked in the early to mid-1970s, the real rate is zero or even
negative, indicating that lenders incorrectly anticipated the price increases
and failed to raise the nominal rates appropriately. Thereafter, however,
they appear to have played it safe by charging higher nominal rates. Given
that inflation came down, this insured relatively high real rates of return.Let's check the
changes in the real rate more directly. Using Transform from the menu bar,
then Compute. . ., calculate the real rate of interest as r = prime rate -
inflation (CPI), and then graph the result. Notice the anomaly of the early
years after World War II. What might explain the pattern? Note also the rise
in r during the early 1980s, and its subsequent decline. If we leave out the
unusual period after World War II and concentrate on 1952-1996, what is the
range for real rates?The federal deficit
is total federal receipts - total federal outlays.Each year the
federal government runs a deficit, it adds to the federal debt, the
total amount of all past borrowing which has not been paid off. The difference
between the debt and the deficit is fundamental; even if we balance the budget,
the debt will continue at its present level until it begins to be paid off.Contrary to everyone's
expectations of just a few years ago, the 1998 federal budget appears to be
balanced and in 1999 it is projected to be in surplus. This will be the first
surplus in nearly 30 years and after the large deficits of the 1980s and early
1990s, it almost seems miraculous. Indeed, President Clinton's 1993 economic
strategy called for several years of spending reductions and tax increases
in order to stop the growth of the deficit and reduce it somewhat. Clinton's
team projected a 1998 deficit of 200 billion, while under the policies of
his predecessor, the deficit was expected to reach 343 billion by 1998. Two
hundred billion is a lot less than 343, but still a big number.Using the graph
function in SPSS, we can easily draw a picture of the federal deficit over
time. First, make sure that all years are selected:
- Choose
Data from the menu bar, then Select Cases . . .;- Click the
All Cases button;- Click Ok.
Then, create the
deficit variable:
- Choose
Transform from the menu bar, then select Compute . . .;- In the
Target Variable box, type deficit;- In the
Numeric Expression box, type fedrec - fedexp;- Click OK;
Now, make the graph:
- Choose
Graphs from the menu bar, then select Line. . .;- In the
Line Charts box, select Simple, and Values of individual cases;- Click Define;
- Highlight
deficit in the variable list box and use the arrow to move it to the Line
Represents box;- Click the
Variable button in the Category Labels box, highlight year in the variable
list box, and move it into the Category Labels box;- Click OK.
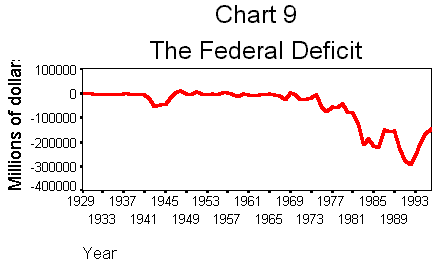
After adding titles
and adjusting the Y axis label, your graph should look like Chart 9.Judging by the
graph in chart 9, it seems that the deficit suddenly exploded in the 1980s.
This may be misleading, however, because we have not controlled for inflation.
Dollars spent in the 1940s of 1950s were far more valuable than dollars spent
in the 1980s or 1990s. If we control for inflation, then comparisons across
time are in terms of dollars with constant purchasing power, so that a 50
billion deficit in the 1940s would be equivalent in purchasing power to a
50 billion deficit in the 1990s. In order to put the deficit in real terms
(i.e., inflation adjusted terms), we must compute a new variable using the
GDP deflator:Real deficit
= [(federal receipts - federal expenditures)/(GDP deflator)] * 100.Calculate the
real deficit and graph it. What do you conclude? When were the largest deficits,
in real terms? Are the big deficits of the 1980s and 1990s still abnormally
large?Another way to
look at deficits and debts is in relation to GDP. That is, how large is the
debt or deficit when it is measured as a share of GDP? Calculating the deficit
or debt as a share of GDP is straightforward, but we first have to take into
account the different units of measurements for each variable. GDP is in billions,
while federal receipts and expenditures are in millions. The simplest procedure
is to put them both in billions by using Transform and Compute to divide Deficit
by 1000. Once the deficit is in billions, then :
Deficit as a
share of GDP = (Deficit/GDP) * 100.The advantage
of treating variables as shares of GDP is that it removes the impact of inflation
since both the numerator and denominator are measured in dollars of the same
purchasing power. Furthermore, the potential importance of variables like
debt depends on the size of the underlying economy. For example, if Bill Gates
has debts of $100 million, its pocket change, whereas for you or me, it would
be financial ruin.What is the deficit,
measured as a share of GDP, in the 1940s, 50s, 60s, 70s, 80s, and 90s? If
we compare the average deficit by decade, did it really get larger in the
1980s in relation to GDP. How does the 1980s compare to the 1970s, or 1940s?SPSS lets us
answer these questions relatively easily. First we will calculate the deficit
as a share of GDP, then we will use the Recode command to create a set of
markers for each of the decades. After that, we will be able to tell SPSS
to calculate the descriptive statistics for each decade using the Compare
Means command.Using the Recode
command, we are first going to create a new variable which will mark each
decade. For example, the new variable, called decade, will be 1 for the 1940s,
2 for the 1950s, and so forth.
- Select
Transform from the menu bar, then Recode, and Into Different Variable;- Highlight
year in the variable list and use to the arrow to move it into the Numeric
Variable -> Output box;- Type decade
in the Output Variable box and click Change;- Click Old
and New Values;- In the
Old Value box, click the Range button and put 1940 and 1949 in the two
boxes;- In the
New Value box type 1 and click Add;- Go back
to the Range boxes and type 1950 and 1959;- In the
New Value box type 2 and click Add;- Repeat
this procedure, for the 1960s and later decades;- Click Continue
and then click OK.Now we are ready
to compare the average deficits.
- Select
Statistics from the menu bar, and choose Compare Means, and then Means;- In the
Dependent List, put the name you gave to the deficit percentage variable;- In the
Independent List put decade;- Click OK.
Which decade has
the largest deficit? Did deficits really increase in the 1980s when they are
measured as a share of GDP? Which decade had the least variation in the size
of the deficit?
1998; Last Modified 14 August 1998











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}